Analysis of TuneIn Radio Stations
Recently I was interested in TuneIn (http://tunein.com) radio service which provides access to radio stations around the globe. In this post I will uncover statistics behind TuneIn radio stations and show how to use the script to do some cool thinks with the TuneIn API.
Output: station_lang.json (6.9 Mb), station_genre.json (6.4 Mb)
I wrote a script stationdigger.py which uses TuneIn API http://inside.radiotime.com/developers/api/opml by traversing tree of links and collecting information about the stations.
TuneIn radio API provides both OPML (XML-like) and JSON formats. You don’t have to have any credentials to use this service. But if you start to use the service frequently you will end up getting 403 Forbidden error. Let’s try to make the first request:
http://opml.radiotime.com/Browse.ashx
Your response will be in default OPML format:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<opml version="1">
<head>
<title>TuneIn</title>
<status>200</status>
</head>
<body>
<outline type="link" text="Local Radio" URL="http://opml.radiotime.com/Browse.ashx?c=local" key="local"/>
<outline type="link" text="Music" URL="http://opml.radiotime.com/Browse.ashx?c=music" key="music"/>
<outline type="link" text="Talk" URL="http://opml.radiotime.com/Browse.ashx?c=talk" key="talk"/>
<outline type="link" text="Sports" URL="http://opml.radiotime.com/Browse.ashx?c=sports" key="sports"/>
<outline type="link" text="By Location" URL="http://opml.radiotime.com/Browse.ashx?id=r0" key="location"/>
<outline type="link" text="By Language" URL="http://opml.radiotime.com/Browse.ashx?c=lang" key="language"/>
<outline type="link" text="Podcasts" URL="http://opml.radiotime.com/Browse.ashx?c=podcast" key="podcast"/>
</body>
</opml>
This is where the story begins. Traversing tree of links with type="link" you can reach links with type="audio" and collect information about the stations. For example, one branch of the link tree can look like:
http://opml.radiotime.com/Browse.ashx
+-- <outline type="link" text="Local Radio" URL="http://opml.radiotime.com/Browse.ashx?c=local" key="local"/>
+-- <outline type="audio" text="San Diego Police Scanners: 2 (Police)" URL="http://opml.radiotime.com/Tune.ashx?id=s103434" bitrate="32" reliability="86" guide_id="s103434" subtext="English" genre_id="g2741" formats="mp3" item="station" image="http://radiotime-logos.s3.amazonaws.com/s103434q.png" now_playing_id="s103434" preset_id="s103434"/>My script stationdigger.py just makes this task automatic and more error prone.
Results Format
I collected statistics for radio stations arranged by language and genre. The results are stored in files station_lang.json (6.9 Mb) and station_genre.json (6.4 Mb) in JSON format for stations by language and genre correspondingly.
Stations by language has the format:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{<language id>:
{"name": <language name>,
"stations":
{<station id>:
{"name": <station name: {text}>,
"description": <station description: {subtext}>,
"url": <station url: {URL}>,
"image": <station image: {image}> ,
"genre": <genre id: {genre_id}>
},
// other stations
}
}
// other languages
}
For example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{"l191":
{"name": "Afrikaans",
"stations":
{"s101967":
{"name": "Radio Namakwaland (Vredendal, South Africa)",
"description": "Afrikaans",
"url": "http://opml.radiotime.com/Tune.ashx?id=s101967&filter=l191",
"image": "http://radiotime-logos.s3.amazonaws.com/s101967q.png",
"genre": "g133",
},
// ...
}
}
// ...
}
Parameter url holds the link to the station stream which you save on your machine and open content of the file with some media player.
For example, open the link in the browser:
http://opml.radiotime.com/Tune.ashx?id=s124197&filter=l1
and in the Tune.ashx file you will find station stream which looks something like:
http://lush.wavestreamer.com:3680/
Open this link, for example, in Banshee Media Player (Media/Open Location) available in Ubuntu as a default media player and enjoy the station :).
Code Analysis
As I mentioned before, stationdigger.py code traverses tree of links and collects information about the stations using DFS algorithm. At first I thought that it will be pretty straightforward to implement the algorithm, but later I realized that I have to handle several issues specific to TuneIn service to properly do it.
TuneIn radio service significantly limits number of calls without partnerId passed (http://inside.radiotime.com/developers/api/opml/security-model#limits). It also has limits for calls even with partnerId but the limit is larger than without partnerId. Once the limit is reached you will start getting 403 Forbidden error for a day. Because of the large number of calls needed to collect the data it is good to have partnerId :) or you can wait for a long time. To collect stations using partnerId it took me about 4-5 days. It is also recommended to pass the serial parameter which can be pretty much anything.
The core of the algorithm is method traverse():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def traverse(self, url):
"Traverses tree of links and populates stations using DFS algorithm"
if not url or (self.numTotal and self.numTotal<self.num):
return
items = self.make_call(url=url)
(audios, links) = self._separate(items)
for item in audios: # check audio links first: playable content
if item.has_key("guide_id") and \
not self._stations.has_key(item.get("guide_id")): # ignore duplicates
self._stations[item.get("guide_id")] = self.to_station(item) # set station
self.num += 1
if self.numTotal and self.numTotal<self.num:
return
for item in links: # check links
self.traverse(item.get("URL"))
In this method it makes call to specified url and returns list of items in the tag. Then it separates links and audio links. Links can later be traversed down the link tree. Audio links are what we are after: they are used to collect information about the station.
The code supports the following features.
Can dig stations both for one and all languages
Because digging stations is a relatively long process, when something happens during the data collection you need a way to restart from some intermediate step. For this purpose the program stores stations in junks: one language in a separate file in a format lang<number>.json
These files are stored in stations directory and then later merged with merge_langs.py script into a single file: station_lang.json. Besides collecting stations for all languages at once you can collect stations just for one language by passing a language tuple.
1
2
3
4
5
6
7
8
def dig_stations_lang(self, filename=None, lang_tuple=None):
"Diggs for stations with language filters"
if lang_tuple:
filters = [lang_tuple] # one language
else:
langjs = self.get_lang() # all languages
filters = self.sorted_tuple(langjs)
self._dig_stations(filters, {"c": "lang"}, filename)
Can dig specified number of stations
You don’t need to collect all stations. Setting limit on total number of stations (self.numTotal) will collect at most this number of stations for the filter passed. See implementation of method traverse(self, url). For example, if filter has two languages then stations will get populated starting from the first language.
Digs only unique stations
To make sure that stations are not duplicated for the same language the program checks if the station has been added before:
1
2
3
4
5
6
def traverse(self, url):
...
if item.has_key("guide_id") and \
not self._stations.has_key(item.get("guide_id")): # ignore duplicates
self._stations[item.get("guide_id")] = self.to_station(item) # set station
...
Handles 403 Forbidden error
This error was a frequent companion during collecting data. This just means that limit of using the TuneIn service has been reached. It not handled properly you will end up either with non-complete stations or no stations at all. I did some experiments with this error and figured out that your program can be rejected either for one day or for a few minutes (not sure how this happens). So I developed some mechanism that handles this error which can be reduced to just one word: persistence! When program receives 403 Forbidden error it waits for some time and then tries to perform the same call again until it receives result other than this error.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def make_call(self, url):
"Makes call and returns response in json format"
if not url:
return None
nurl = self._set_format(url)
if nurl in self._urls: # Avoid circular reference
return None
result = -1 # to enter the loop
while (result == -1):
try:
req = urllib2.Request(nurl, headers=self._headers())
response = urllib2.urlopen(req)
page = self._decompress(response.read()) # decompress
pdict = json.loads(page)
result = pdict.get("body") # interested in "body" section only: should be list
self._urls.add(nurl) # URL is processed
except urllib2.HTTPError, e:
if e.code == 403:
result = -1
else:
result = None
except:
result = None
if result == -1:
print "Waiting %s --> %s" % (self.num, nurl)
time.sleep(WAIT_TIME)
return result
Avoids circular reference
From experience I found out that some links might have circular reference: referring to itself in one or several hops. Once the program enters the circular reference it can get stuck forever! Simple check can save you out of trouble:
1
2
3
4
5
def make_call(self, url):
...
if nurl in self._urls: # Avoid circular reference
return None
...
Response compression
To optimize the stream of responses I added header to request encoded content supported by most of the popular web servers and decompress it on the program’s side:
Accept-Encoding: gzip
Here is the method which performs decompression:
1
2
3
4
5
def _decompress(self, s):
"Decompresses string"
sio = StringIO(s)
file = GzipFile(fileobj=sio)
return file.read()
Handles embedded links
Another issue I had related to TuneIn responses is embedded tags which looked like in xml format:
<outline text="Stations" key="stations">
<outline type="audio" text="Radio Pretoria (Kleinfontein)" URL="http://opml.radiotime.com/Tune.ashx?id=s10616&partnerId=my_partner_id&serial=123&filter=l191" bitrate="32" reliability="96" guide_id="s10616" subtext="Tienie se musiek" genre_id="g255" formats="wma" show_id="p149910" item="station" image="http://radiotime-logos.s3.amazonaws.com/s10616q.png" current_track="Tienie se musiek" now_playing_id="s10616" preset_id="s10616"/>
</outline>To handle this issue I traverse also these subtrees:
1
2
3
4
5
6
7
8
9
10
11
12
def _traverse_outline(self, items, audios, links):
"Traverses children outline elements and populate audios and links lists"
if not items: # No items
return
for item in items:
if item.has_key("children") and item.get("children"):
self._traverse_outline(item.get("children"), audios, links)
elif item.get("type") == "audio":
audios.append(item)
elif item.get("type") == "link":
links.append(item)
Mimics headers of Chrome browser
For some reason passing browser headers with the call doesn’t reject calls as fast as without the headers. So I decided to explore Chrome browser headers and pretend that the calls are made with the browser. Here is the example of the headers presented as a Python dictionary:
1
2
3
4
5
6
7
8
9
headers = {
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"User-Agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.71 Safari/534.24",
"Accept": "application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5",
"Accept-Encoding": "gzip",
"Accept-Language": "en-US,en;q=0.8",
"Accept-Charset": "ISO-8859-1,utf-8;q=0.7,*;q=0.3"
}
Using Script
Before you start running program it is recommended to set config.txt file first:
[general]
partnerId =
serial =
To collect stations for all languages you need to iterate over sorted languages:
1
2
3
4
5
sd = StationDigger()
langjs = json.load(open("generated/lang.json"))
lang = sd.sorted_tuple(langjs)
for n in range(len(lang)):
sd.dig_stations_lang("stations/lang%s.json" % n, lang_tuple=lang[n])
so the session for calls without partnerId passed looks like:
Finished: Aboriginal, total: 2
Finished: Afrikaans, total: 12
Waiting 15 --> http://opml.radiotime.com/Browse.ashx?id=g373&filter=l210&render=json
If you want to just dig stations for n-th language then the script will do the work:
1
2
3
4
5
sd = StationDigger()
langjs = json.load(open("generated/lang.json"))
lang = sd.sorted_tuple(langjs)
lang_tuple = lang[n]
sd.dig_stations_lang("stations/lang%s.json" % n, lang_tuple=lang_tuple)
Other Useful Scripts
Besides implementing stationdigger.py I also implemented some useful scripts performing some operations on generated files.
merge_langs.py
This script merges files with stations by a single language into one file: station_lang.json. You need to have language files already generated from stations collections. The file structure should look like:
stations/
lang0.json
lang10.json
...
lang2genre.py
It turns out that the stations by language can be converted into stations by genre because most of the stations have also genre field. This way one can collect statistics of station distribution by genre. lang2genre.py script converts station_lang.json into station_genre.json.
status_generator.py
This script uses station_lang.json and station_genre.json to generate cumulative statistics on languages and genres. The result is later used to draw plots.
draw_plots.py
Script for generating pie and histogram plots for languages and genres.
Plotting Results
This is the final step in our analysis. We take data generated by status_generator.py script and use draw_plots.py to create plots for languages and genres. To draw plots I used matplotlib – an advanced plotting Python library extensively used by scientists. I used pie and histogram plot types to represent data in two different ways. I wasn’t happy with the default color schema so I wrote function which generates html-type colors from HSV colors.
Here are the results I obtained:
Results Analysis
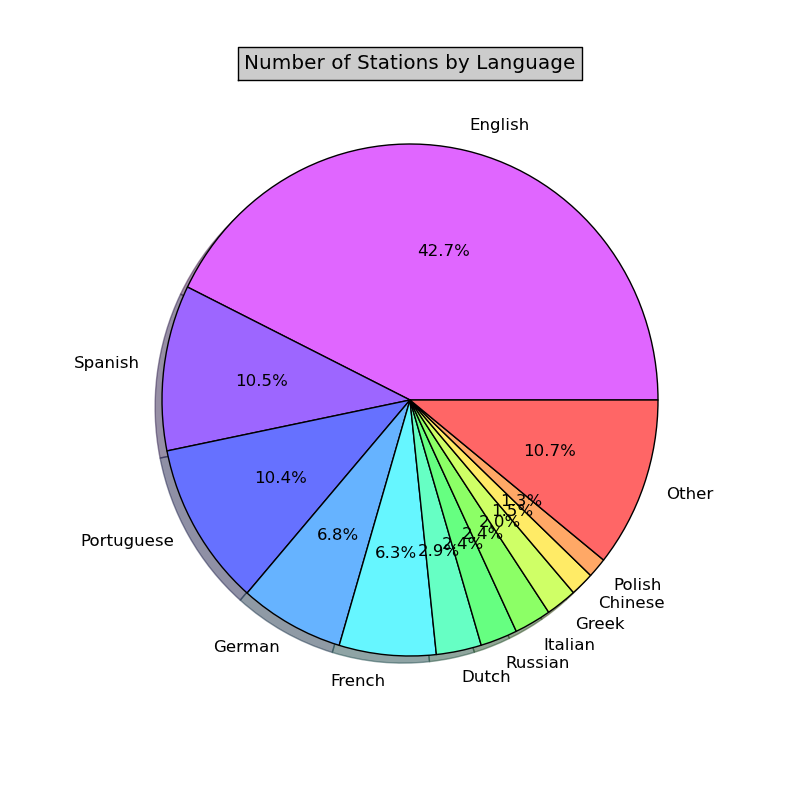
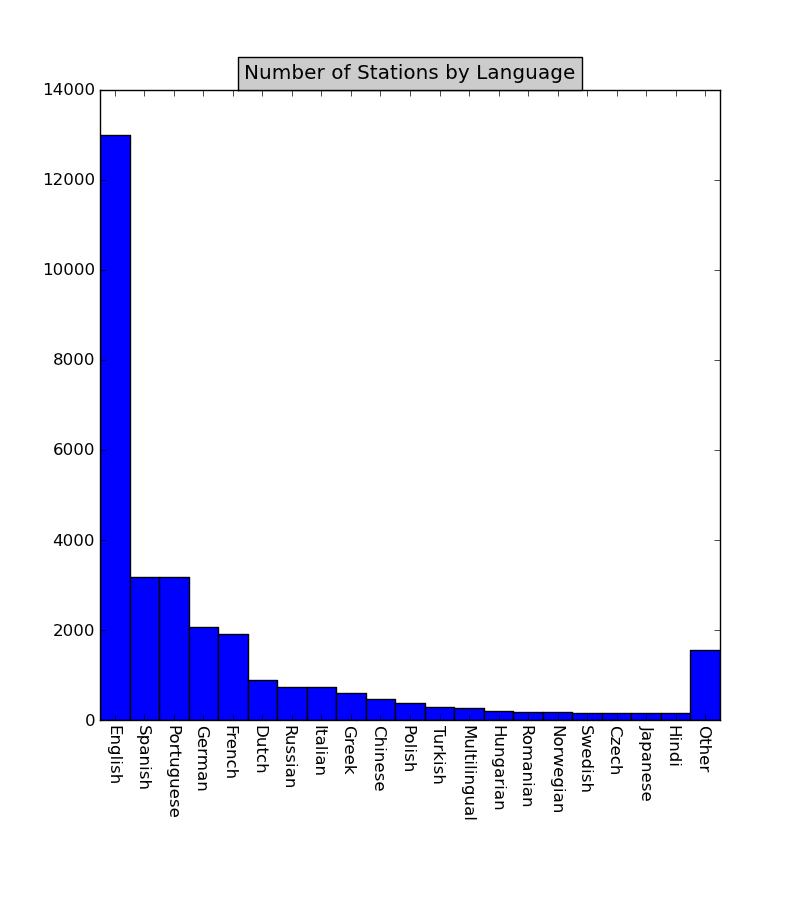
It is no surprise that TuneIn radio service is a US based company so probably they are more biased to English language. English speaking stations comprise 42.7% of all provided stations. Next popular language, Spanish and Portuguese, have about 10% each.
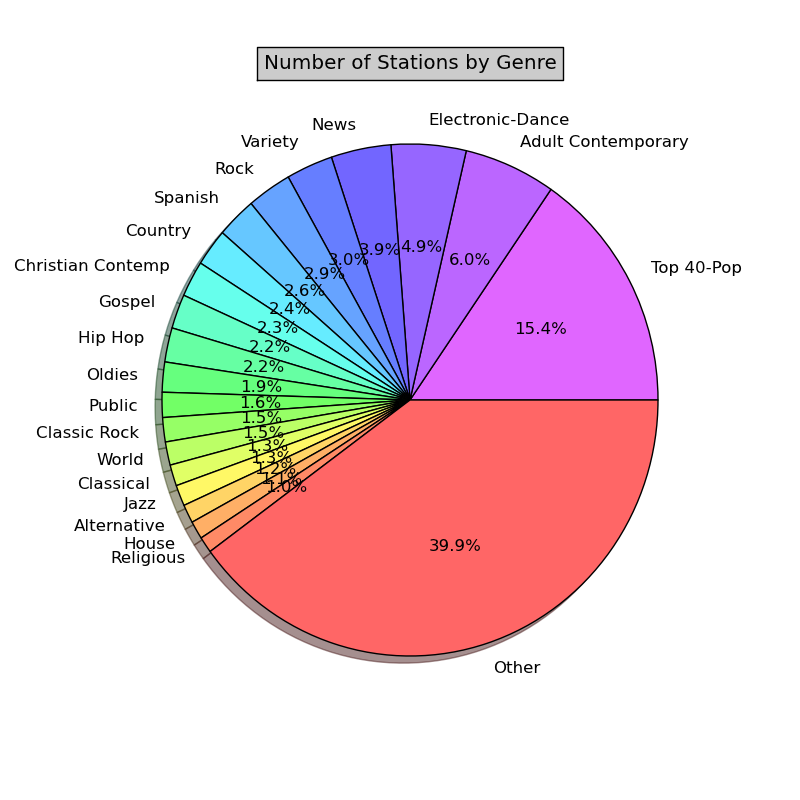
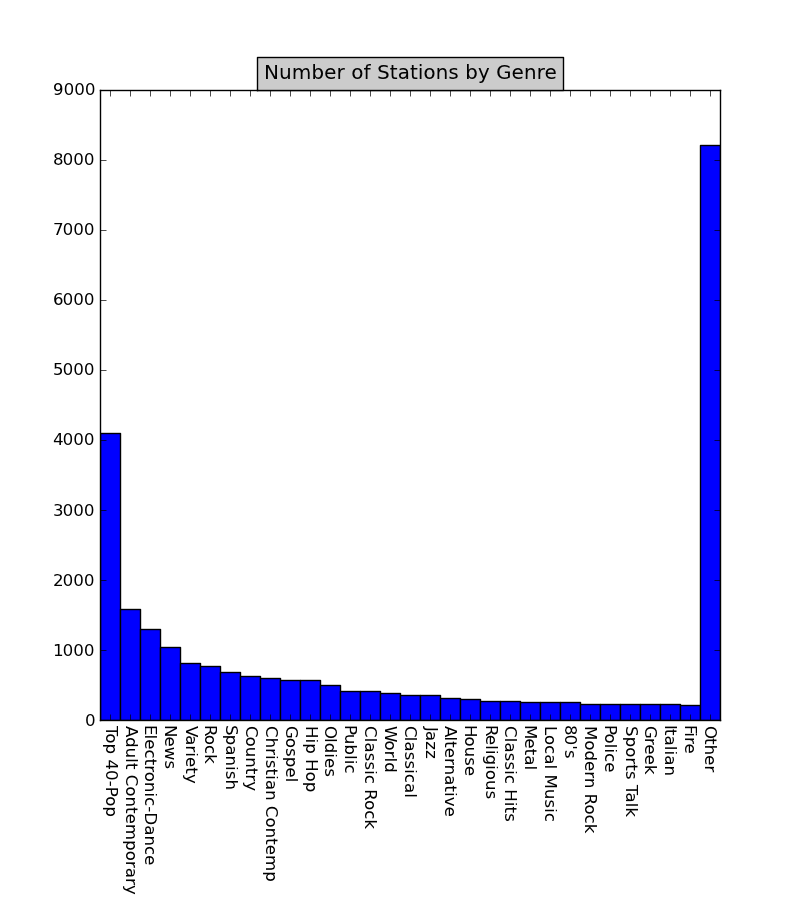
Genre distribution is not that narrow as for languages. Majority of stations feature pop genre (Top 40-Pop: 15.4% and Adult Contemporary: 6.0%) which is also predictable. Detailed statistics can be found in status_lang_sort.txt and status_genre_sort.txt.